文字コードのカオスな世界を整理してみた
仕事で使うかもしれないので
文字コード¶
なんか仕事でやりそうだったので、この際カオスだった文字コード云々を整理してみる。
概要¶
文字セットと符号化方式¶
まず、文字セット(文字集合)と符号化方式という概念を理解することが必要。
文字セットとは¶
アルファベットや記号はもちろん、漢字やひらがな、ハングルやヘブライ文字など、世界中で使われている文字を集めたもの。
Unicodeは文字集合です。
Unicodeは便宜上、Unicodeスカラ値(16進数にU+をつけて U+0000~U+20FFFF で表現)という値で文字を管理しています。
Unicodeスカラ値はコードポイントという呼ばれ方をすることもあります。厳密には意味が違いますが、ここでは同じものだと思っておけば大過ありません。
符号化方式とは¶
文字セットで定義されている一つ一つの文字を、どのように符号化するかという文字符号化方式(エンコーディング)です。
Unicodeという一つの文字集合に対して、異なる文字符号化方式UTF-8、UTF-16が存在し、符号化した結果も異なります。
UTF-8とUTF-16の符号化方式の実装例¶
| Unicodeスカラ値 | 文字 | 説明 | UTF-8 | UTF-16 |
|---|---|---|---|---|
| U+0041 | A | ラテン文字 | 41 | 0041 |
| U+0061 | a | ラテン文字 | 61 | 0061 |
| U+00E8 | è | ラテン文字 | C3 A8 | 00E8 |
| U+042F | Я | キリル文字(ロシア) | D0 AF | 042F |
| U+05D0 | א | ヘブライ文字 | D7 90 | 05D0 |
| U+0905 | अ | デーヴァナーガリ文字 | E0 A4 85 | 0905 |
| U+0E04 | ค | タイ文字 | E0 B8 84 | 0E04 |
| U+2162 | Ⅲ | ローマ数字 | E2 85 A2 | 2162 |
| U+3042 | あ | ひらがな | E3 81 82 | 3042 |
| U+4E9C | 亜 | 漢字(あ) | E4 BA 9C | 4E9C |
| U+D558 | 하 | ハングル | ED 95 98 | D558 |
| U+103A0 | 𐎠*1 | 楔形文字 | F0 90 8E A0 | D800 DFA0 |
| U+2000B | 𠀋 | 漢字(じょう) | F0 A0 80 8B | D840 DC0B |
| U+20BB7 | 𠮷 | 漢字(よし) | F0 A0 AE B7 | D842 DFB7 |
| U+29E3D | 𩸽 | 漢字(ほっけ) | F0 A9 B8 BD | D867 DE3D |
*1…昔はフォントがなくて表示できていなかったんですが、今は表示できてますね
文字セットと符号化方式の関係¶
ここ超重要
なんか等幅フォントじゃないと表示が崩れるようになってしまいました
表示が崩れている場合のためにスクリーンショットも貼っておきます
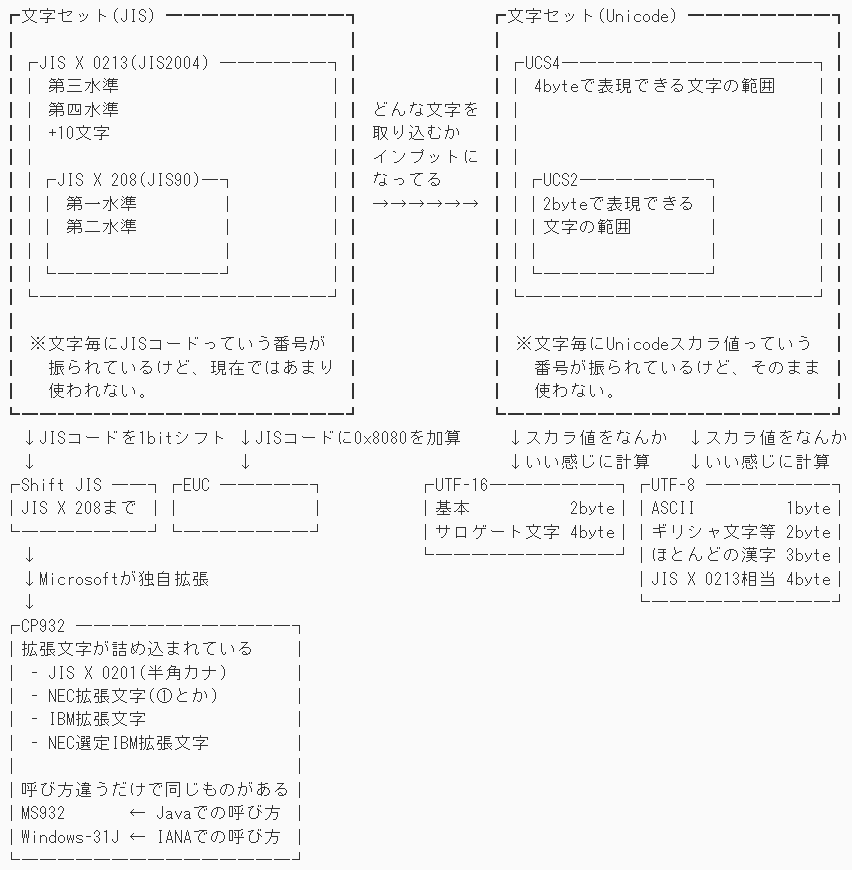
┏文字セット(JIS) ━━━━━━━━━━┓ ┏文字セット(Unicode) ━━━━━━━━┓
┃ ┃ ┃ ┃
┃┌JIS X 0213(JIS2004) ──────┐┃ ┃┌UCS4──────────────┐┃
┃│ 第三水準 │┃ ┃│ 4byteで表現できる文字の範囲 │┃
┃│ 第四水準 │┃ どんな文字を ┃│ │┃
┃│ +10文字 │┃ 取り込むか ┃│ │┃
┃│ │┃ インプットに ┃│ │┃
┃│┌JIS X 208(JIS90)─┐ │┃ なってる ┃│┌UCS2───────┐ │┃
┃││ 第一水準 │ │┃ →→→→→→ ┃││2byteで表現できる │ │┃
┃││ 第二水準 │ │┃ ┃││文字の範囲 │ │┃
┃││ │ │┃ ┃││ │ │┃
┃│└─────────┘ │┃ ┃│└─────────┘ │┃
┃└────────────────┘┃ ┃└────────────────┘┃
┃ ┃ ┃ ┃
┃ ※文字毎にJISコードっていう番号が ┃ ┃ ※文字毎にUnicodeスカラ値っていう ┃
┃ 振られているけど、現在ではあまり ┃ ┃ 番号が振られているけど、そのまま ┃
┃ 使われない。 ┃ ┃ 使わない。 ┃
┗━━━━━━━━━━━━━━━━━━┛ ┗━━━━━━━━━━━━━━━━━━┛
↓JISコードを1bitシフト ↓JISコードに0x8080を加算 ↓スカラ値をなんか ↓スカラ値をなんか
↓ ↓ ↓いい感じに計算 ↓いい感じに計算
┌Shift JIS ──┐┌EUC ─────┐ ┌UTF-16───────┐┌UTF-8 ───────┐
│JIS X 208まで ││ │ │基本 2byte││ASCII 1byte│
└───────┘└───────┘ │サロゲート文字 4byte││ギリシャ文字等 2byte│
↓ └──────────┘│ほとんどの漢字 3byte│
↓Microsoftが独自拡張 │JIS X 0213相当 4byte│
↓ └──────────┘
┌CP932 ────────────┐
│拡張文字が詰め込まれている │
│ - JIS X 0201(半角カナ) │
│ - NEC拡張文字(①とか) │
│ - IBM拡張文字 │
│ - NEC選定IBM拡張文字 │
│ │
│呼び方違うだけで同じものがある│
│MS932 ← Javaでの呼び方 │
│Windows-31J ← IANAでの呼び方 │
└───────────────┘
JIS X 0213(JIS2004)とUTF-16(サロゲート文字)とUTF-8(4Byte文字)の微妙な関係¶
UTF-16(サロゲート文字)¶
サロゲート文字に、JIS X 0213(JIS2004)の文字が、 だいたい 入っている。
ただ、2Byte範囲の方にも入っているので、完全に対応していない。
UTF-8(4Byte文字)¶
UTF-8(4Byte文字)に、JIS X 0213(JIS2004)の文字が、 だいたい 入っている。らしい。
(本当かどうか未確認)
みんなの混乱を招く、混同している所¶
Shift JIS と CP932の混同¶
- Windowsは、ANSIと呼んたりする。それCP932や。。
- CP932をShift JISと呼んでるソフトやOSがあるが、厳密には間違っている。
同じものなのに呼称が異なる¶
- CP932,MS932,Windows-31J 同じもんや・・・しかも、これらが Shift JISと混同される
UnicodeとUTF-16・UTF-8の混同¶
Unicodeは、文字セットであり、文字コードでは無いが、一部のソフトやOSで混同している。
- Windowsでは、Unicodeと言えば、UTF-16を指している
サロゲートペア・サロゲート文字の混同¶
本来は、UTF-16の2byte範囲で表現しきれない文字に対して、名付けられた名称である。
が、UTF-8の4Byte文字に対して、サロゲート文字と誤って呼ぶケースが多い。
EBCDIC+JEF¶
蛇足だが、レガシーシステムの文字コードはこんな感じ。
┌EBCDIC──┐ ┌JIS X 028(JIS90)──────────┐
│ASCIIとは │ │そのままのJISコード値を使うが、 │
│別の独自の│+│どこから漢字かが、判らないので │
│文字コード│ │KI:漢字イン │
│ │ │KO:漢字アウト │
│ │ │と呼ばれる制御コードで囲む必要がある│
└─────┘ └──────────────────┘
hidekatsu-izuno 日々の記録 - JEF4J をリリースしてみた。あるいは、メインフレームの文字コードの話。
http://hidekatsu-izuno.hatenablog.com/entry/2018/01/14/140124
UTF-8の4Byte文字(または、サロゲートペア)は、何が面倒なのか¶
UTF-8から、CP932(または、Shift JIS)への変換ができない¶
UTF-8の4Byteは、すべからくJISの第三水準・第四水準文字であるから、CP932(または、Shift JIS)には変換できない。
Windowsは「JIS第3・第4水準はUnicodeで対応する(Shift JISには追加しない)」というスタンスらしい。
DB保存ができない¶
MySQLもOracle Database同様にUTF-8で文字を保存できる。ところが、4Byte文字を想定していないために、4バイトとなる文字を格納できない。
プログラミングが面倒¶
byteとして扱った瞬間から、文字数のカウントやら、どれがサロゲート文字なのか判定が必要やら、考慮しなきゃいけないことが増えまくる。
容量の見積もりが面倒¶
実際は、DBの容量見積もりとかも含めて、もっと大きなスケールになると思うけど。
100文字記録されるファイルが100個あるとするじゃん?
1文字2byteだったら、
2byte * 100文字 * 100ファイル ≒ 20kbyte じゃん?
でも、UTF-8だと、1文字1byte~4byteじゃん?
しょうがないから、最大値で見積もるじゃん?
4byte * 100文字 * 100ファイル ≒ 40kbyte で倍になるじゃん?
でも、サロゲート文字で埋め尽くされることは無いだろうから、容量の無駄じゃん?
「容量の無駄なんでちょっと減らしときますね^^」とか、お客さんに説明できないじゃん?
文字コードにおける諸所のトラブル原因¶
波ダッシュ問題¶
Unicodeの字形の登録ミスに起因して、以下の状態になっています。
-
波ダッシュ 〜
- WAVE DASH(ユニコードポイント : U+301C)
-
全角チルダ ~
- FULLWIDTH TILDE(ユニコードポイント : U+FF5E)
- Shift JIS には存在しない
同じ字形に見えますね。Windowsなどでは波ダッシュの代用として全角チルダが不適切に使われるので混乱の元となっています。Macで入力した"〜"とWindowsで入力した"~"は違うものとして扱われます。仮にパスワードや、パスワードを忘れた際の合言葉に使っていた場合「あれ~MacではログインできるのにWindowsではログインできないな~」ということになります。
寿司ビール問題¶
🍣🍺という文字を扱えないソフトウェアがあるという所から名付けられた問題です。UTF-8において、1文字4Byteの文字を考慮しないかったことに起因した不具合でした。最近は、この不具合を抱えたソフトウェアは少なくなりました。
Unicode/UTF-8のあまり知られていない仕様¶
サロゲートペア¶
まとめ中
𩸽
Unicode結合文字¶
橋本商会 - UTF-8-MACをUTF-8に変換する
http://shokai.org/blog/archives/5953
Unicode正規化 変換するワンライナー¶
Unicode正規化するシェル芸を作りました
python3で
echo -n "DQⅢ①⑳海海神神㌔㍉ビデブー" | python -c "import sys,unicodedata; print(unicodedata.normalize(\"NFKC\", sys.stdin.read()));"
DQIII120海海神神キロミリビデブー
perlで
echo -n "DQⅢ①⑳海海神神㌔㍉ビデブー" | perl -e "use strict;use utf8;use Encode;use Unicode::Normalize;binmode STDIN, ':encoding(UTF-8)';binmode STDOUT, ':encoding(UTF-8)';print Unicode::Normalize::NFKC(<STDIN>);"
DQIII120海海神神キロミリビデブー
検出する方法について¶
異字体セレクタ¶
まとめ中
Article¶
Qiita - 絵文字を支える技術の紹介
https://qiita.com/nonanona/items/b148c212ba7c24942e93
絵文字がある種のUnicodeバグを世界から一掃しつつある件について
https://note.mu/ruiu/n/nc9d93a45c2ec
書籍¶
たかが文字コード、されど文字コード/ShiftJISerへ贈る鎮魂歌
https://techbookfest.org/product/5677280795820032?productVariantID=5733665126481920
ユニコード戦記 ─文字符号の国際標準化バトル
https://amzn.to/3redEnc
[改訂新版]プログラマのための文字コード技術入門 WEB+DB PRESS plus
https://amzn.to/3KY0276
参考¶
Shapecatcher(手書きの文字からUnicodeを検索)
https://shapecatcher.com/#
(プログラマのための)いまさら聞けない標準規格の話
https://www.ogis-ri.co.jp/otc/hiroba/technical/program_standards/part1.html
ㇹ゚ン゚'ㇳ̃ヴ゙ニ゙コ゚ヮヰ文̂字̠コ゚−ト゚ノ゙ㇵナ゚ㇱ(現在に至るまでの文字コードの軌跡と簡単な使い方について)
https://heppoko.hatenadiary.jp/entry/2018/04/28/184559
ウナのIT資格一問一答 - 文字コードやフォント、その他PC関連の読み物です。
http://una.soragoto.net/topics/index.html
JISから迫る文字コード入門
https://speakerdeck.com/todokr/jiskarapo-ruwen-zi-kodoru-men
hidekatsu-izuno 日々の記録 - JEF4J をリリースしてみた。あるいは、メインフレームの文字コードの話。
http://hidekatsu-izuno.hatenablog.com/entry/2018/01/14/140124
長くて覚えやすくて複雑なパスワードとemojiの話
https://speakerdeck.com/ozuma/chang-kutejue-eyasukutefu-za-napasuwadotoemojifalsehua
Dive Into Python 3 第4章.文字列
http://diveintopython3-ja.rdy.jp/strings.html
C++標準化委員会、ついに文字とは何かを理解する: char8_t
https://qiita.com/yumetodo/items/54e1a8230dbf513ea85b
アプリの国際化の舞台裏
https://speakerdeck.com/niw/apurifalseguo-ji-hua-falsewu-tai-li
Unicodeで絶対知っておくべきセキュリティ5つの注意(翻訳)
https://techracho.bpsinc.jp/hachi8833/2017_11_28/48435
UTF-8の冗長なエンコード
https://gihyo.jp/admin/serial/01/charcode/0004#sec2
全ての開発者が知っておくべきUnicodeについての最低限の知識
https://gigazine.net/news/20231005-unicode/
絵文字を支える技術について
https://note.com/ttuusskk/n/n1bff5d8e638c
Attacking with Character Encoding for Profit and Fun ~趣味と実益の文字コード攻撃~
https://www.blackhat.com/presentations/bh-jp-08/bh-jp-08-Hasegawa/BlackHat-japan-08-Hasegawa-Char-Encoding.pdf
文字コードの話
https://speakerdeck.com/qnighy/encoding
文字体系とユニコード入門
https://r12a.github.io/scripts/tutorial/part2
コメント