A painter and a black cat: 同人誌印刷所見学ツアーで見学させて頂きました
以下のイベントに参加しました
※1人で2つも参加するの遠慮してたのですが、緑陽社の方が直前でキャンセルがあったため急遽参加しましたラッキー
TL;DR¶
- 2つの印刷方式がある
- オンデマンド印刷(とよく呼ばれるもの): デカくて高性能なプリンタで印刷する方式
- オフセット印刷: 版と呼ばれるアルミ板をつかって印刷する方式
- どっちの方が綺麗に印刷できるかという観点においては、近年においてはほぼ差はなく、(インクがテカリ気味/そうじゃない、とかの)個人の好みに近い
- これらの機器はビッッックリするほど高い
- レーザープリンタもあったすごい切れる(小並感)
- トンボについても質問してきたので後述の「トンボ付け足し君」に活きそう
しまや出版¶
ねこちゃんおる天国かな
いろんな加工ができる旨、ご紹介頂きました
おそよ本で可能なことはなんでもできそうです
この金属板がオフセット印刷の版だそうです(社長見切れております)
それでこれがオフセットの印刷機
オフセットとオンデマンド印刷の違いは僅かですが、インクのテカリのような差があるとのこと(でも、どちらがよいかという話ではなく好みの問題)
これは中綴じ(平綴じ)する機会だそうで、この針金で綴るそうです
紙もすんごい種類がある(迷う)
帰りに50周年記念の冊子を頂きました!(ありがとうございます!)
かわいいやばい
緑陽社¶
直前でキャンセルあったので来れたうれしい
オフセット印刷の版がこれ
緑陽社さんはグッズも作成しているそうで、これは缶バッジ作成マシーン(作ったものを頂いてしまった…!)
オフセット印刷機
C(シアン)とM(マゼンタ)のインクがセットされているのが見えます。
見えない箇所にY(イエロー)もセットされています。
シアンとマゼンタの色からするとけっこう原色の赤と青っぽく見えますね。印刷時に薄く伸ばされるとマゼンタやシアンに見えるのでしょう。
とう言うわけで、4枚の版にCMYKそれぞれの色をつけて印刷するのだそう
最終的な一枚はフルカラーに見えるのだと
これは加湿器だそうで、しまや出版さんにもありました。
湿度はめっちゃ気を使っているそう。
これは無線綴じする時の糊だそう。触ってみるとプラスチック片みたいに硬いです。
帰りにバッチやアクキーを頂きました!(ありがとうございます!)
トンボ付け足し君¶
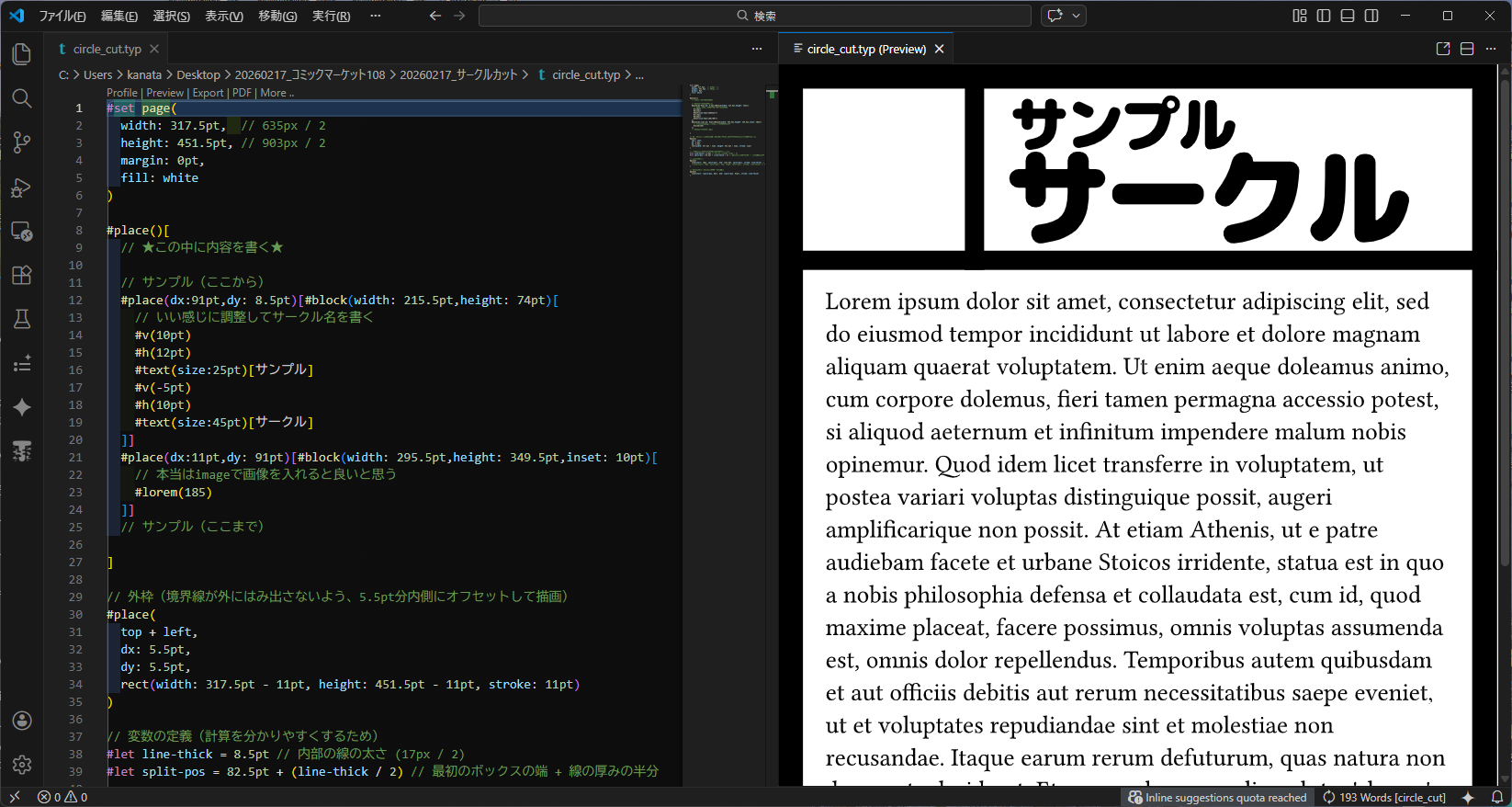
2026/4/11から頒布予定の縦書きTypstに、任意のPDFにトンボをくっつける機能「トンボ付け足し君」を作っています。トンボを付ける必要がある印刷所さんに対しても、必要ない印刷所さんに対しても、気にせずにどっちにも出すこともできるようにしたくて作っています。
いったんトンボなしでPDF原稿を作って、トンボ必要な印刷所さんに対しては「トンボ付け足し君」でトンボつければいい訳です。最高でしょ。
それで、トンボの仕様について確認できるチャンスでしたので、しまや出版さんにも、緑陽社にも、質問させて頂いた次第です。
コーナートンボはだいたい各社さん同じ
こんな感じ
センタートンボはまちまち
こんな感じ
それで、「こういうトンボは困る…とかありますか…?」と質問させて頂きました。
結論としては2社さまとも「どういうのでも大丈夫やで~」と回答頂きました。
ということで、仕様的にはこれでいいんじゃないかな、と思っています。
「トンボ付け足し君」を使うとどうなるかイメージをはっておきます。
こういう原稿のPDFがあるとして
「トンボ付け足し君」を使うとこんな感じになります。
塗り足しがあっても大丈夫です(クリックすると拡大)。
ちなみにガイドラインも付け足すことができます(クリックすると拡大)。
赤い線が断ち切り線で、ここを目標に断裁されるのですが多少ズレる可能性があって、その範囲が外側の黒い線(塗り足し線)と内側の青い点線(文字はこの範囲に収める)になります。
あと、隠しノンブル付け足し機能もあります。